Transfer Relationships via Prompt for Medical Image Classification
Abstract
Method
Pipeline
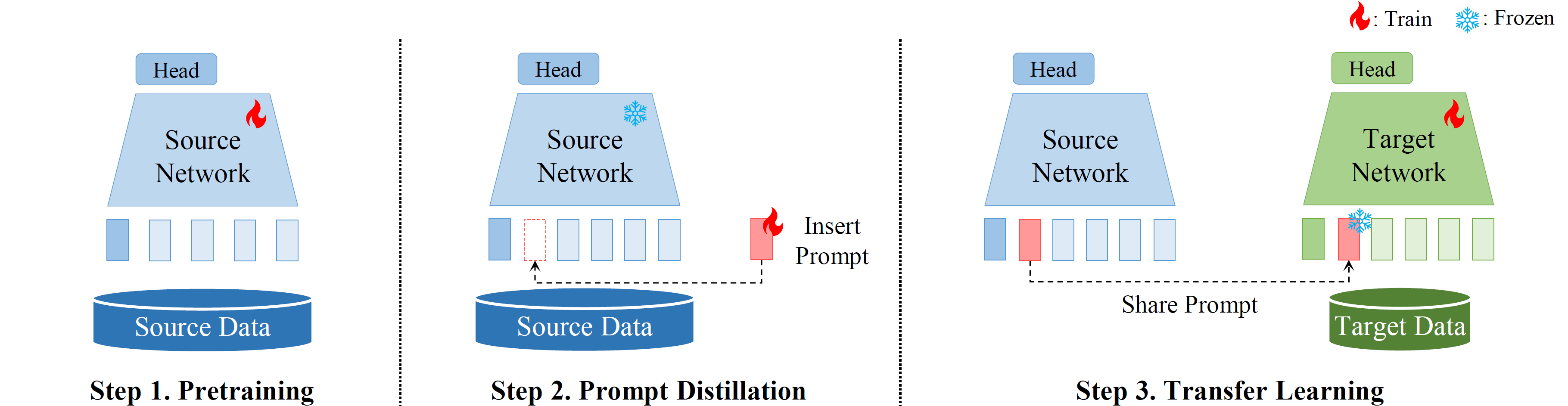
The pipeline of Prompt Distillation based transfer learning. After pre-training, prompts are inserted inside the pre-trained source network and trained for a few epochs (Step 2). Then, these learned prompts are shared in place of network weights to target networks for transfer learning (Step 3). ``Train" and ``Frozen" refer to whether backpropagation is performed, which involves calculating the gradients and updating the parameters, or not.
Prompt Distillation
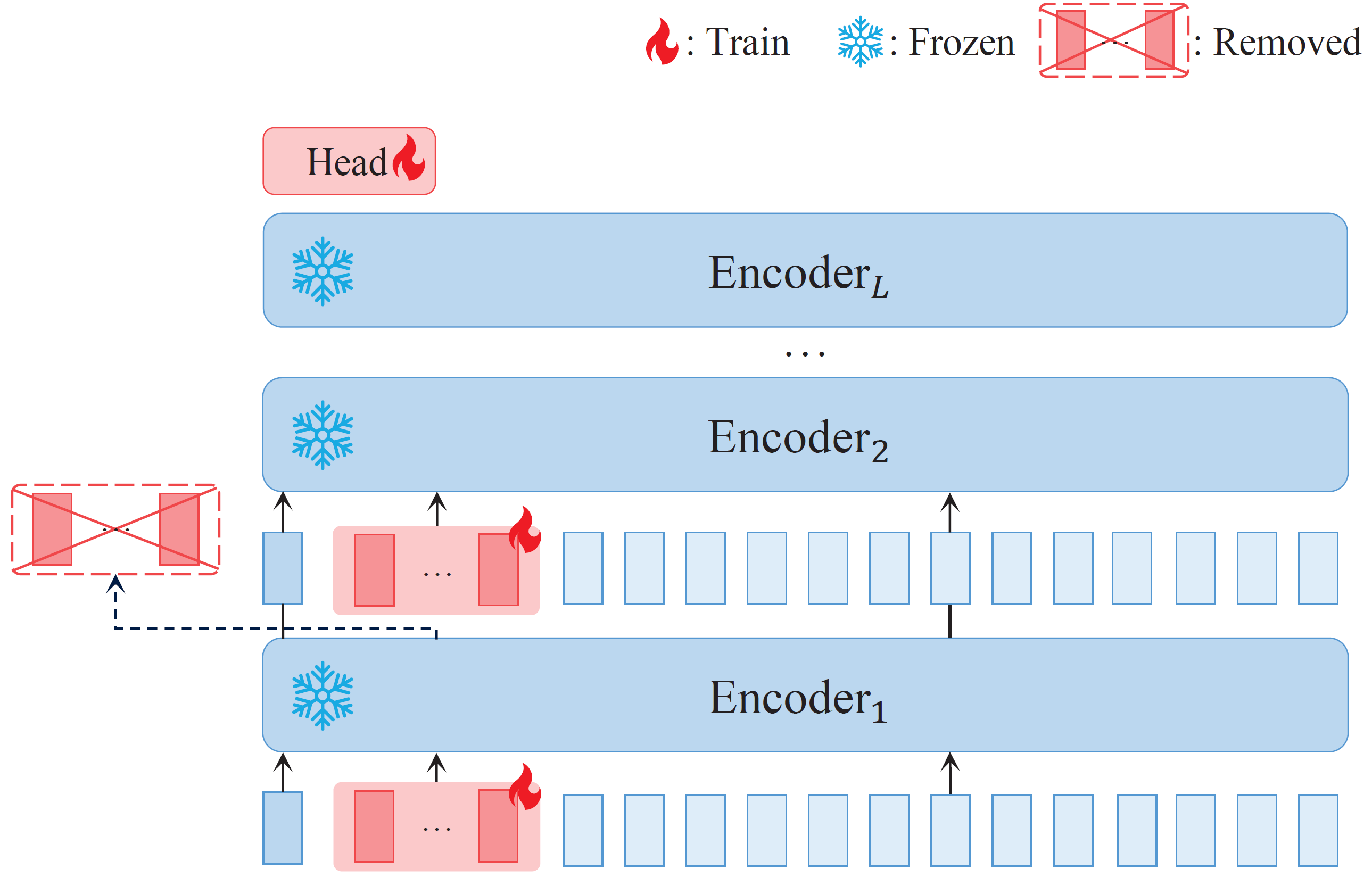
The framework of prompt distillation. Red tokens represent prompts, which are injected into Transformer encoders. During prompt distillation, Transformer remains frozen (i.e. not back-propagated), and only prompts are trained (i.e. back-propagated). Prompts from the previous layer are removed as new prompts are inserted into the next layer.
Quantitative Results
Transfer Learning via Prompt Distillation
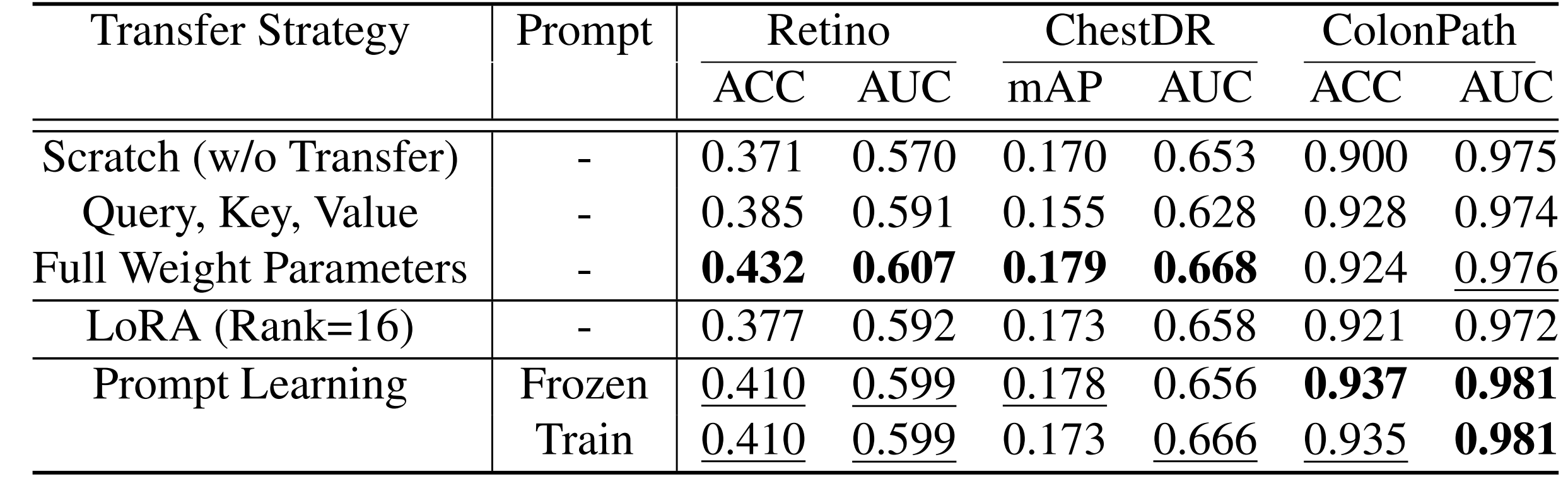
Quantitative results of prompt distillation compared to the scratch learning and full-weights transfer learning on three domains. Prompt distil- lation enhances performance beyond scratch and close to full-weight transfer learning. An interesting point is that in ColonPath, where domain shifts are large, transferring relationships solely through prompt distillation enhances the performance of the target network.
Enhancing Already-trained Networks
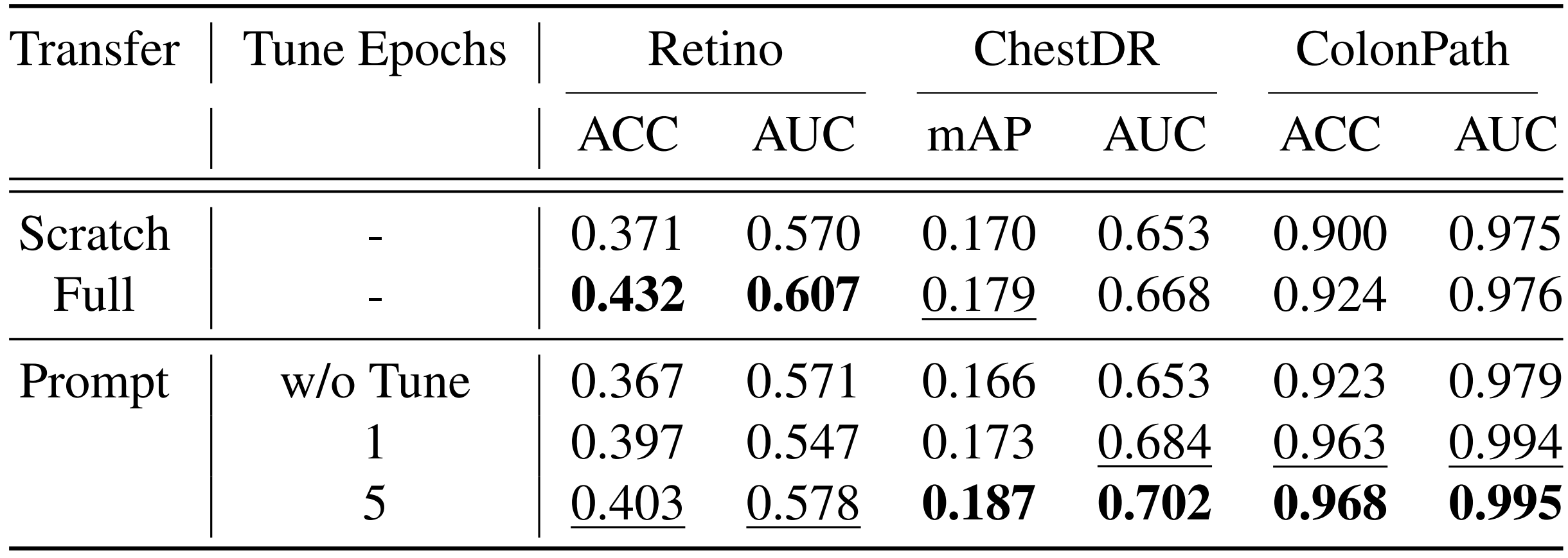
Improvements in the performance of already-trained networks are observed through the synergistic adaptation between the existing network weights and distilled prompts.
Knowledge Compression Strategies
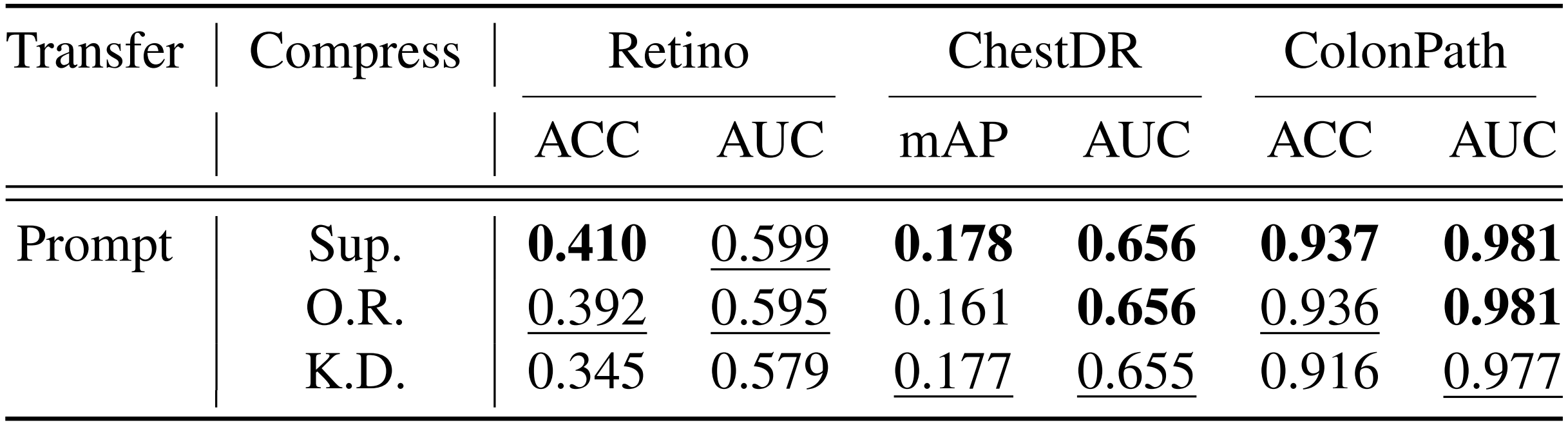
Sup.: Supervised Learning, O.R.: Ordered Representation Learning, K.D.: Knowledge Distillation.
Comparing distinct knowledge compression strategies. Supervised learning is effective and efficient overall. It outperforms other methods with a straightforward objective, no need for structural modifications, and is easily applicable to any network.
Quantitative Ablation
The Number of Prompt Embeddings
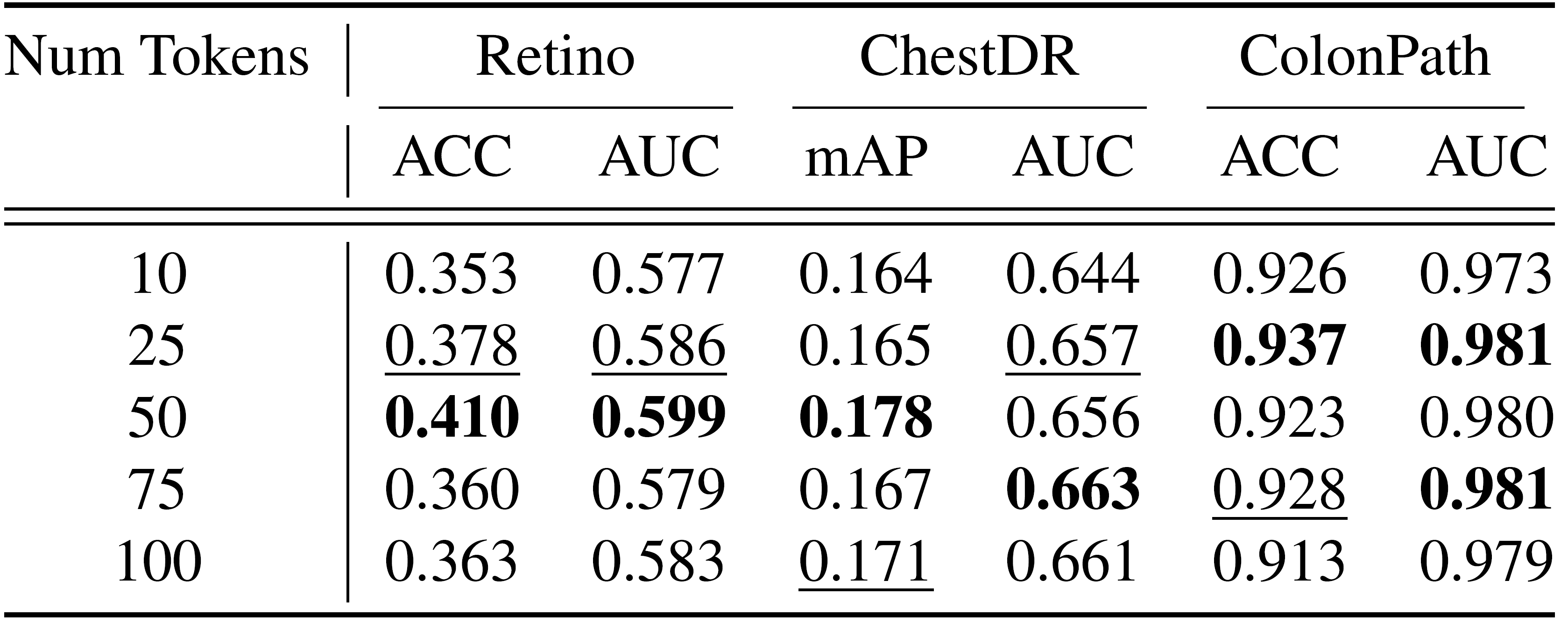
The effect of the number of prompt embeddings in transfer learning performance. Too few prompts are insufficient for effectively compressing knowledge, while too many disrupt the attention.
BibTeX
@article{promptdistill2024,
author = {Choi, Gayoon and Kim, Yumin and Hwang, Seong Jae},
title = {Prompt Distillation for Weight-free Transfer Learning},
month = {July},
year = {2024},
}