EAGLE🦅: Eigen Aggregation Learning for Object-Centric Unsupervised Semantic Segmentation
Abstract
Video
Method
Pipeline
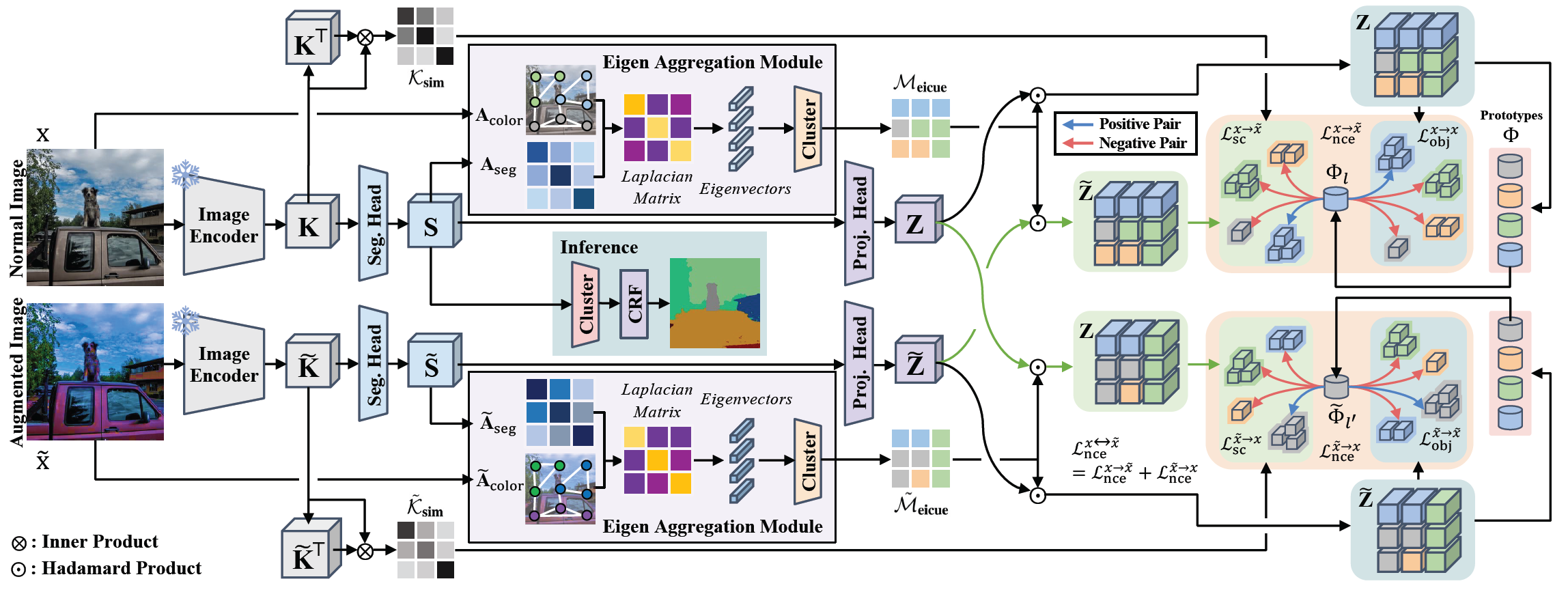
The pipeline of EAGLE. Leveraging the Laplacian matrix, which integrates hierarchically projected image key features and color affinity, the model exploits eigenvector clustering to capture object-level perspective cues defined as \( \mathrm{\mathcal{M}}_{eicue} \) and \( \mathrm{\tilde{\mathcal{M}}_{eicue}} \). Distilling knowledge from \( \mathrm{\mathcal{M}}_{eicue} \), our model further adopts an object-centric contrastive loss, utilizing the projected vector \( \mathrm{Z} \) and \( \mathrm{\tilde{Z}} \). The learnable prototype \( \mathrm{\Phi} \) assigned from \( \mathrm{Z} \) and \( \mathrm{\tilde{Z}} \), acts as a singular anchor that contrasts positive objects and negative objects. Our object-centric contrastive loss is computed in two distinct manners: intra(\( \mathrm{\mathcal{L}}_{obj} \))- and inter(\( \mathrm{\mathcal{L}}_{sc} \))-image to ensure semantic consistency.
Eigen Aggregation Module
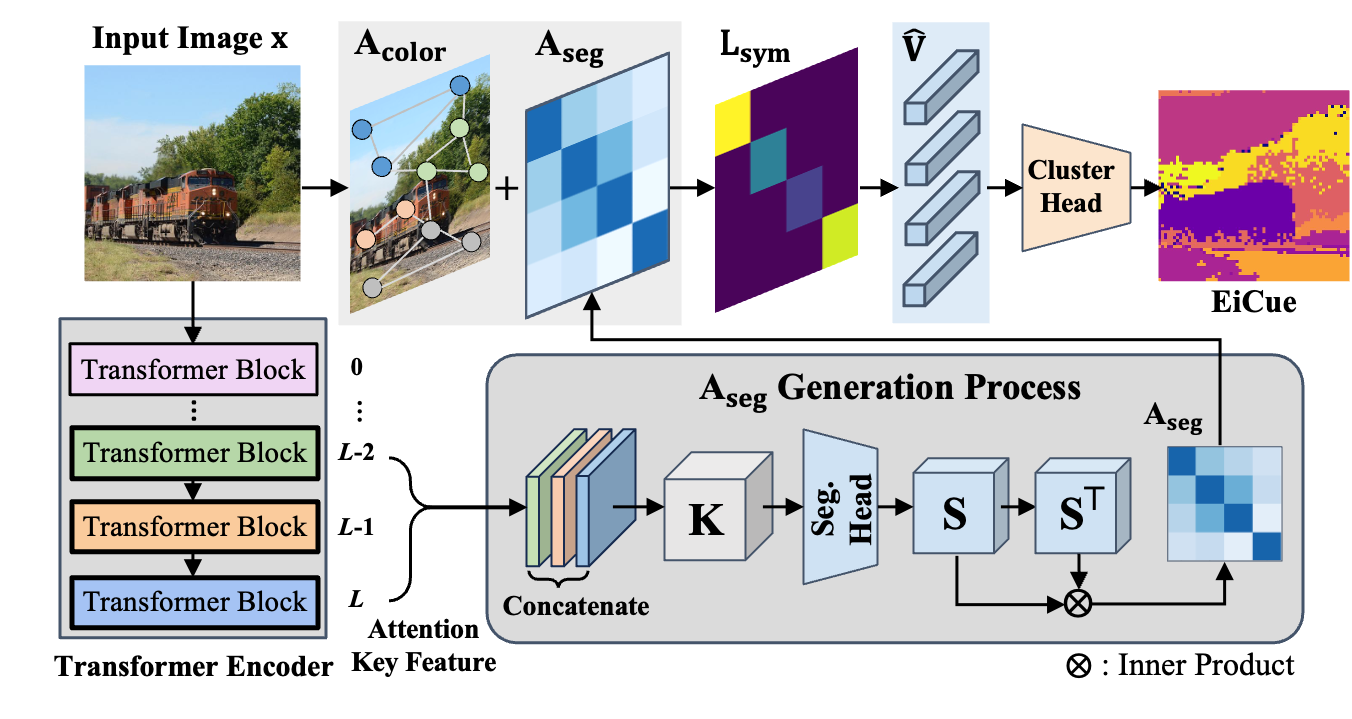
An illustration of the EiCue generation. From the input image, both color affinity matrix \( \mathrm{A_{color}} \) and semantic similarity matrix \( \mathrm{A_{seg}} \) are derived, which are combined to form the Laplacian \( \mathrm{L_{sym}} \). An eigenvector subset \( \mathrm{\hat{V}} \) of \( \mathrm{L_{sym}} \) are clustered to produce EiCue.
Visualization of Primary Elements
Eigenvectors








Visualizing eigenvectors derived from \( \mathrm{S} \) in the Eigen Aggregation Module. These eigenvectors not only distinguish different objects but also identify semantically related areas, highlighting how EiCue captures object semantics and boundaries effectively.
EiCue









Comparison between K-means and EiCue. The bottom row presents EiCue, highlighting its superior ability to capture subtle structural intricacies and understand deeper semantic relationships, which is not as effectively achieved by K-means.
Qualitative Results
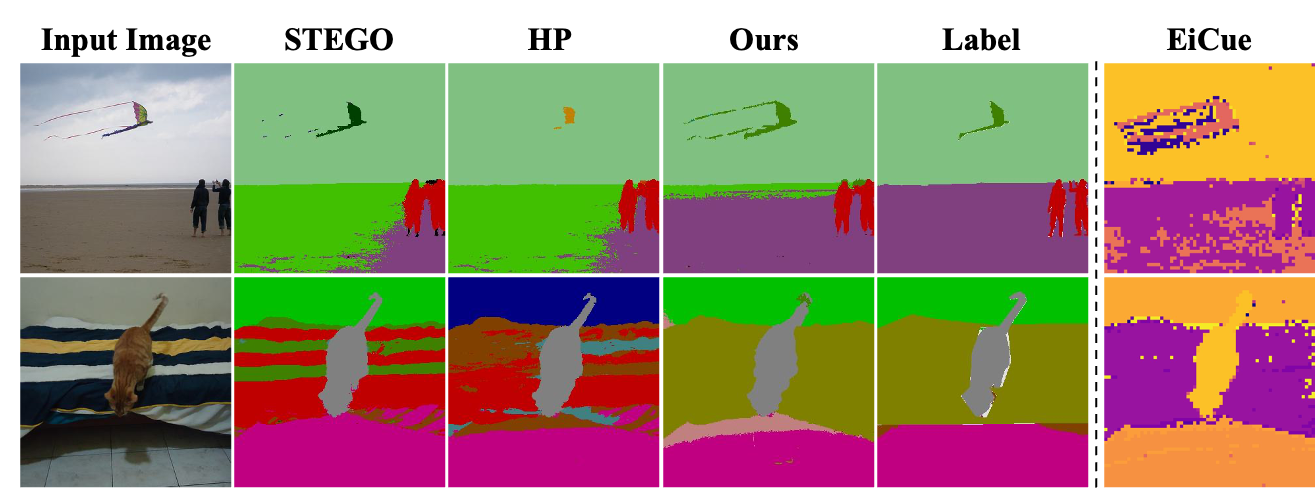
COCO-Stuff






Qualitative results of COCO-Stuff dataset trained with ViT-S/8 backbone.
Cityscapes





Qualitative results of Cityscapes dataset trained with ViT-B/8 backbone.
Potsdam-3
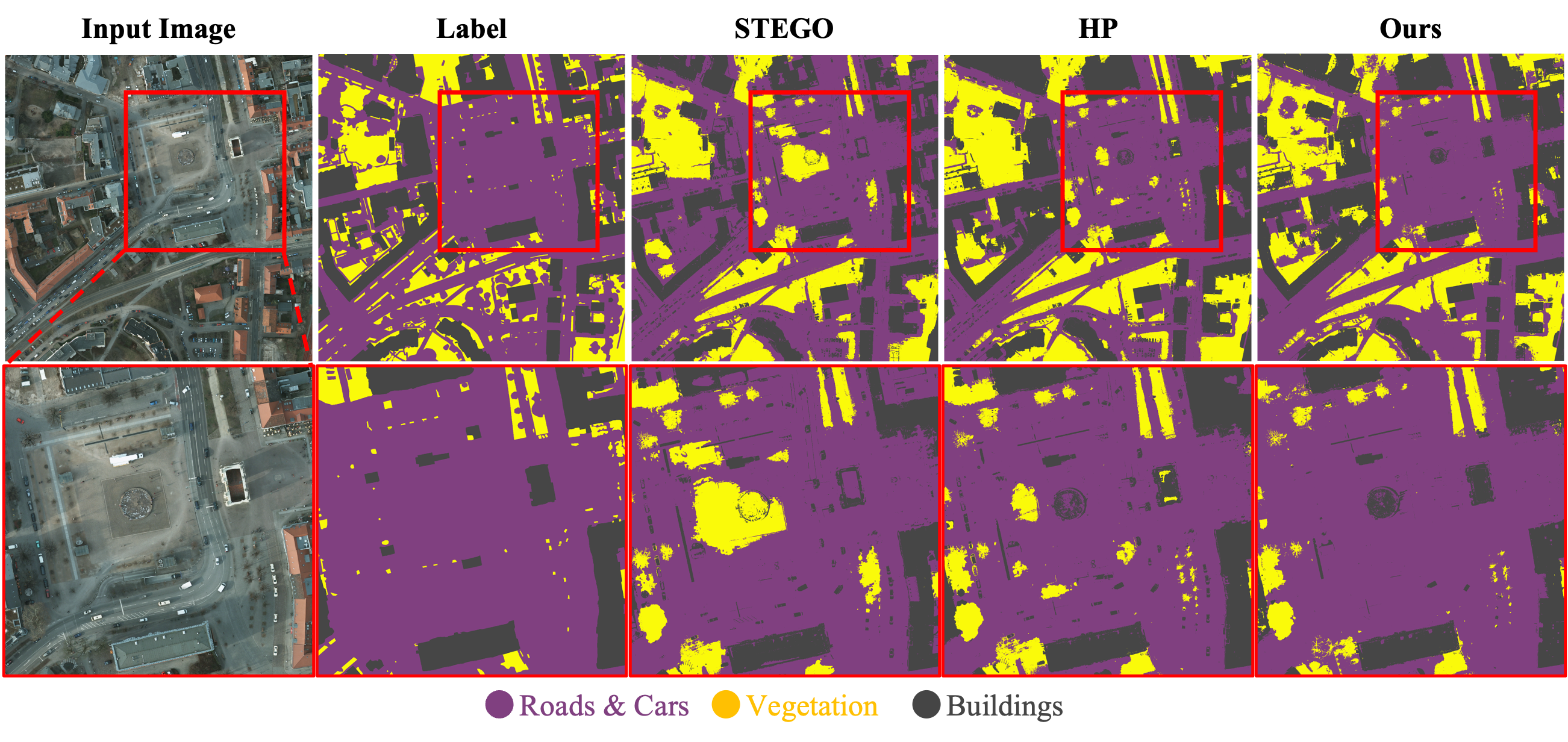
Qualitative results of Potsdam-3 dataset trained with ViT-B/8 backbone.
Quantitative Results
COCO-Stuff
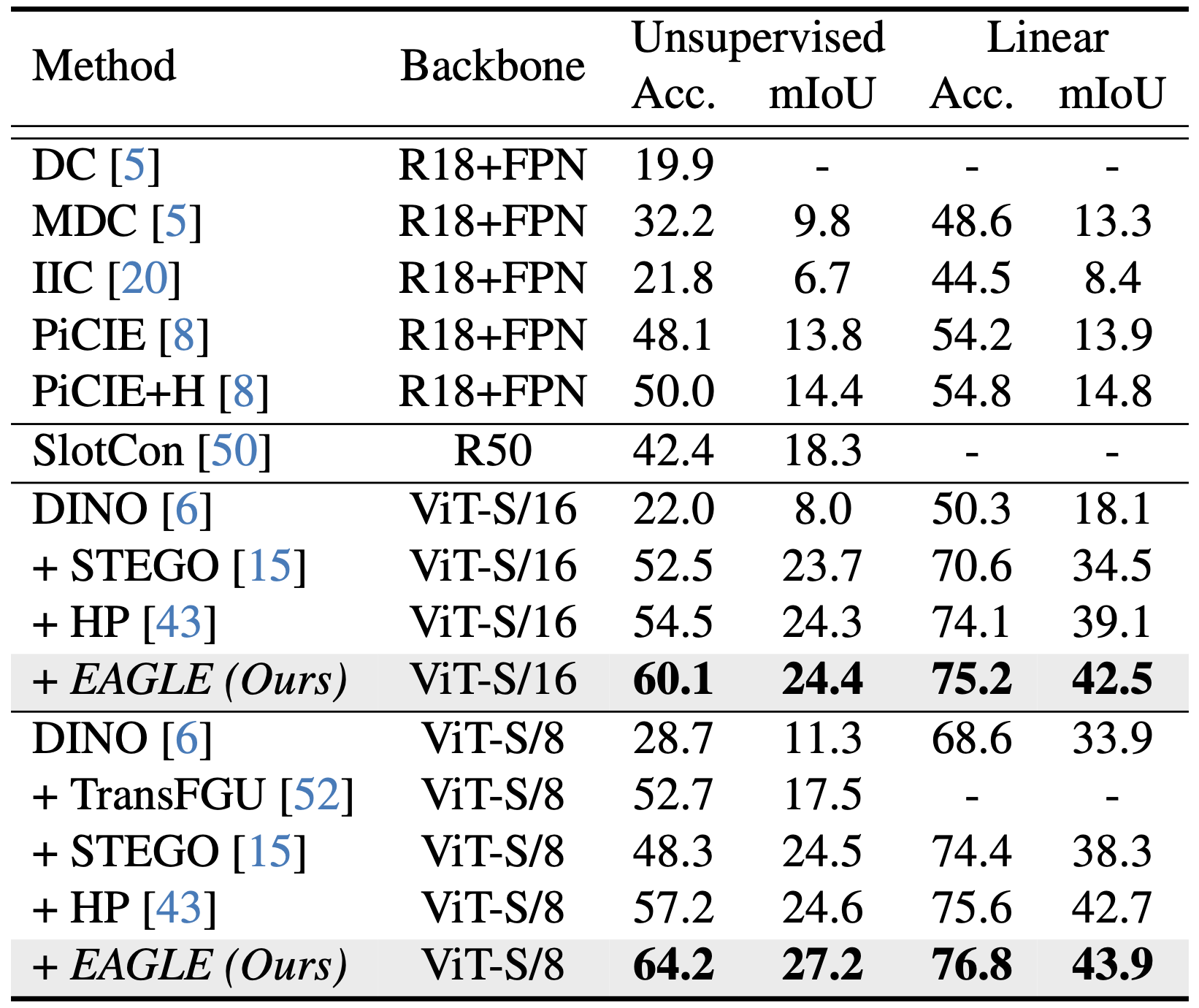
Quantitative results on the COCO-Stuff dataset.
Cityscapes
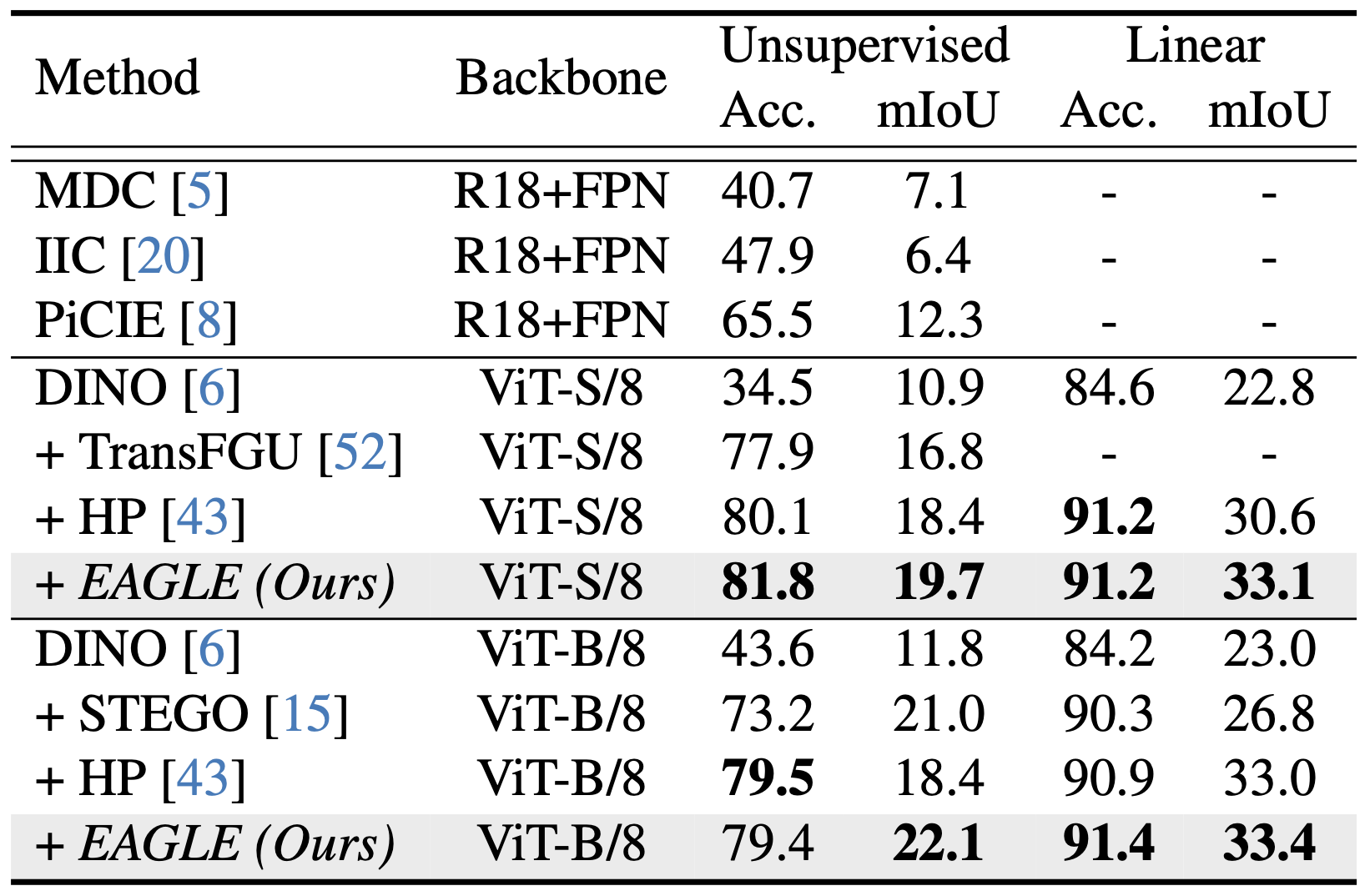
Quantitative results on the Cityscapes dataset.
Potsdam-3
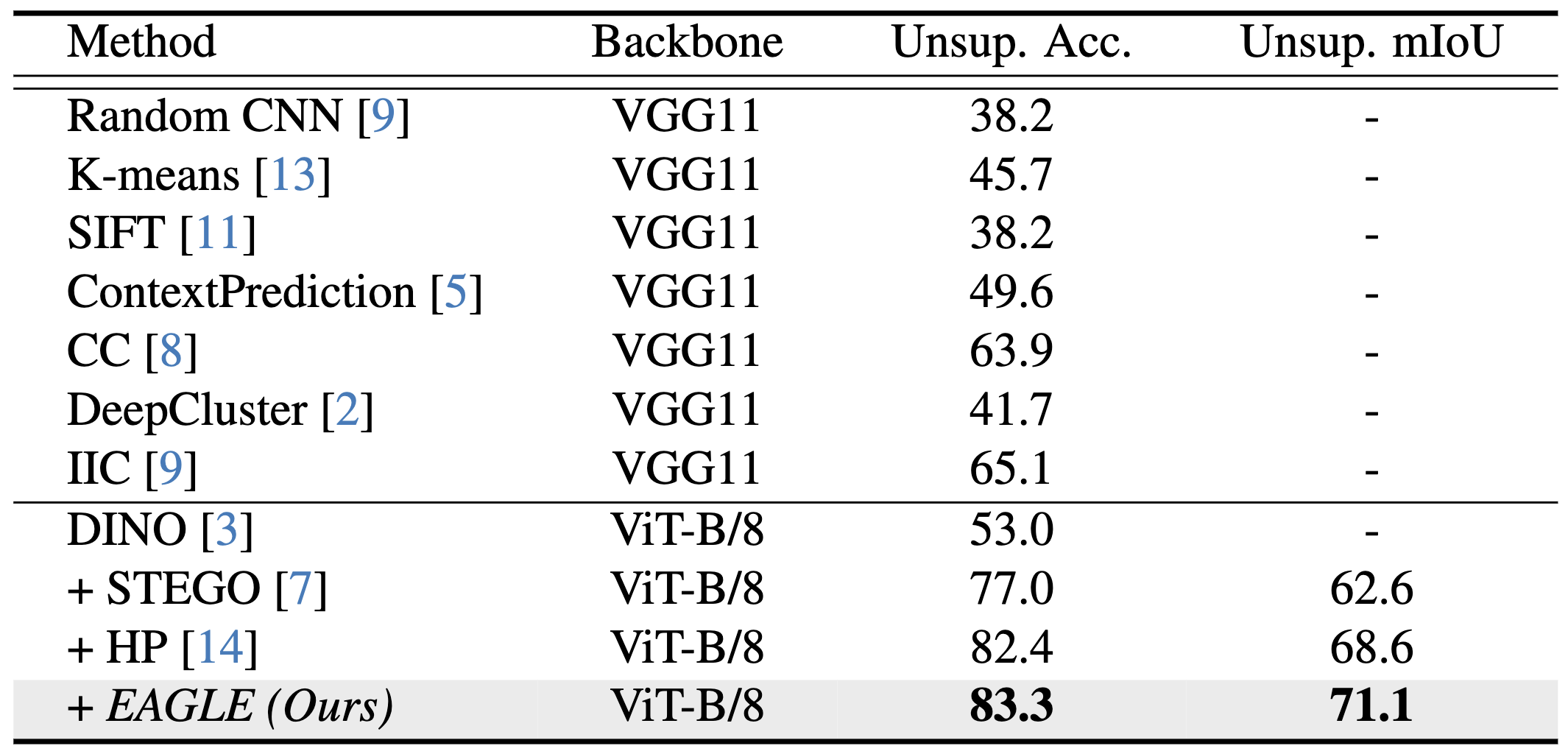
Quantitative results on the Potsdam-3 dataset.
BibTeX
@InProceedings{eagle2024,
author = {Kim, Chanyoung and Han, Woojung and Ju, Dayun and Hwang, Seong Jae},
title = {EAGLE: Eigen Aggregation Learning for Object-Centric Unsupervised Semantic Segmentation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {3523-3533}
}